Ils nous ont rejoint : découvrez le témoignage de Christophe, Gautier et Gaspard !

Aujourd’hui nous vous proposons de découvrir Christophe, Gautier et Gaspard, trois jeunes talents qui ont rejoint Corexpert en 2020. Découvrez leurs profils, leurs parcours et leurs choix de rejoindre Corexpert sous forme d’interview. Bonne lecture !

Interview croisée
Comment avez-vous découvert Corexpert ?
Christophe : « J’ai découvert Corexpert par Internet. En effet, je voulais travailler dans le secteur du Cloud AWS et je devais effectuer ma formation à Lyon. J’ai donc cherché les entreprises faisant du Cloud à Lyon et je suis tombé sur Corexpert. »
Gautier : « J’ai découvert Corexpert grâce à une personne de mon réseau. »
Gaspard : « Fin 2018 je cherchais un stage de première année de Master qui me permettrait de progresser sur AWS, j’ai donc naturellement postulé de manière spontanée via le site de Corexpert. Après le stage, j’ai prolongé l’aventure avec Corexpert grâce à un contrat de professionnalisation dans le cadre de l’alternance avec les cours de ma deuxième année de Master. »
Pourquoi avoir choisi le Cloud ? Et pourquoi le Cloud d’AWS ?
Christophe : « Dans le vaste monde des réseaux, beaucoup de domaines m’intéressaient et, ne sachant pas par où commencer, je me suis dit : « commence dans une entreprise ‘traditionnelle’ d’architecture réseaux et tu verras bien si ça te plait ». Cependant, je n’étais pas bien sûr de mon raisonnement. J’ai alors appelé des amis ayant suivis le même parcours que moi pour me conseiller et l’un d’entre eux m’a suggéré de faire du Cloud, secteur très porteur dans les années à venir. Après quelques recherches dans ce domaine, mon choix s’est naturellement tourné vers le Cloud AWS, leader du marché (et de loin). »
Gautier : « Pour moi, le Cloud est un passage obligé pour les entreprises actuelles et futures en termes d’agilité et de réduction des coûts. C’est à mon sens LA solution à privilégier. Travailler au sein d’une entreprise qui est partenaire AWS répond totalement à mes ambitions d’avenir. Amazon est le leader mondial du cloud computing, les grandes entreprises utilisent les services AWS, intégrer Corexpert assure une collaboration avec le numéro un du marché. »
Gaspard : « Lors de ma licence professionnelle j’ai eu l’occasion de découvrir quelques services du Cloud D’Amazon. Cette première expérience m’ayant particulièrement plu, je souhaitais absolument poursuivre dans ce domaine et approfondir mes connaissances. »
Quel est votre parcours ?
Christophe : « Après le lycée, j’ai intégré la classe préparatoire CPE Lyon. Une fois l’école intégrée, j’ai passé deux ans dans la filière Sciences du Numérique en me spécialisant les six derniers mois dans le domaine des réseaux. Après ces deux ans, j’ai fait une année de césure, et j’en ai profité pour faire un stage dans l’entreprise Infineon Technologies à Munich dans le but d’améliorer mes compétences techniques et ma maîtrise des langues étrangères.
Cependant, une fois là-bas, j’ai compris que pour gagner en expérience rapidement, je ne devais pas intégrer la dernière année du cycle d’ingénieur de manière traditionnelle (six mois de formation suivi de six mois de stage). J’ai découvert qu’il était possible de faire un diplôme en alternance à Lyon 1, le master SRIV, en parallèle de mes études à CPE Lyon. Et j’ai opté pour cette seconde option. »
Gautier : « Je suis étudiant en informatique, et j’ai obtenu un bac scientifique mention bien en 2018. A l’issue, j’ai été admis dans une école d’ingénieur, cependant au bout d’un semestre j’ai décidé d’intégrer l’IUT Informatique directement en Janvier 2019 qui correspondait plus à mes attentes. L’obtention du DUT Informatique est prévue en Janvier 2021. »
Gaspard : « J’ai commencé mes études par un DUT Informatique à Valence, pour donner suite à mon stage de fin de diplôme réalisé à Lyon, j’ai choisi de poursuivre avec une licence professionnelle DEVOPS à l’Université Lyon 1. Malgré la licence professionnelle qui théoriquement mène à l’emploi, j’ai fait le choix de continuer mes études et j’ai passé deux ans à Vichy dans le cadre du Master SIPPE (Stratégie d’Internet et Pilotage de Projet en Entreprise) de l’Université Clermont-Auvergne. »
Qu’attendiez-vous de votre stage/alternance chez Corexpert ?
Christophe : « J’attends de mon stage chez Corexpert de gagner en expérience et en autonomie dans le domaine du Cloud tout en vérifiant que c’est bien un secteur qui me correspond et qui me plait. »
Gautier : « J’espère accroître mes connaissances et mes compétences sur les services AWS le plus possible, et particulièrement celles centrées purement informatique tels que l’algorithmie… etc. »
Gaspard : « Mon stage et mon année d’alternance étaient pour moi l’occasion de confirmer mon choix d’orientation professionnelle tout en approfondissant mes compétences sur AWS. »
Sur quels sujets avez-vous travaillés durant votre stage/alternance chez Corexpert ?
Christophe : « J’ai commencé mon stage il y a peu, je suis donc en pleine découverte de la plateforme AWS, étape indispensable avant de travailler avec des clients. »
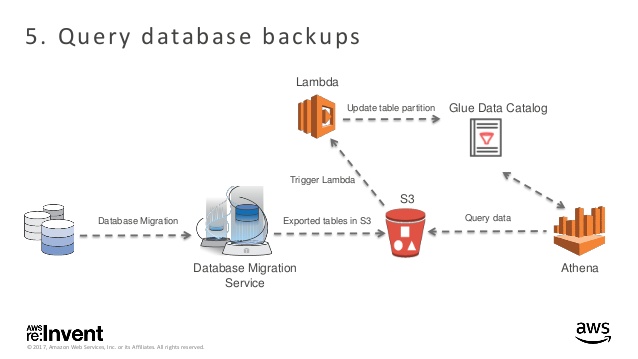
Gautier : « Tout d’abord, durant les premiers jours j’ai découvert les services AWS avec mon maître de stage afin de basculer vers un projet concret. Puis, après ces quelques jours d’intégration j’ai migré vers un projet interne à l’entreprise qui consiste à développer une application web permettant de visualiser un certain nombre de paramètres (les coûts, le stockage…etc) des projets en cours, à venir et effectués de Corexpert. »
Gaspard : « Durant mon stage j’ai eu l’opportunité de participer au développement d’applications web React et d’infrastructures AWS Serverless, à la fois sur des projets internes à Corexpert ou sur des Proof of Concepts. Lors de l’alternance j’ai pu poursuivre le développement de projets internes et ainsi voir le cycle de vie complet d’un projet AWS, mais j’ai aussi eu la possibilité de participer au développement de projet client. »
Comment s’est passé votre intégration chez Corexpert ?
Christophe : « Je suis arrivé à Corexpert fin septembre 2020 c’est-à-dire en pleine crise du Covid 19. J’ai pu commencer à travailler à la Tour pendant un peu plus de trois semaines et l’ambiance était très bonne (malgré le fait qu’une grande partie de mes collègues étaient en télétravail). »
Gautier : « J’ai intégré Corexpert le 2 Novembre 2020, la semaine qui a suivi l’annonce du deuxième confinement. L’intégration s’est très bien déroulée, malgré le distanciel. J’ai pu découvrir mes collègues de manière virtuelle mais j’espère les rencontrer d’ici la fin de mon stage. »
Gaspard : « Les « weekly meetings » et les « code review » m’ont permis de bien m’intégrer au sein du pôle développement, tout en ayant une vision d’ensemble des projets en cours, des technologies utilisées et des contextes clients. De manière plus global les ateliers (REX, veille technologique, Hackathon) du vendredi après-midi, les pauses déjeuners et les parties de baby-foot m’ont permis d’apprendre à connaitre chaque collaborateur de Corexpert. »
Dans quel cadre de travail avez-vous évolué ? Comment s’est passé l’adaptation au contexte actuel (télétravail, distance, confinement, etc…) ?
Christophe : « Comme j’ai pu le dire dans la réponse précédente, j’ai commencé à travailler à la Tour avant de migrer chez moi à cause du confinement. Personnellement, je n’ai pas trop de mal à travailler chez moi puisque j’ai de la place et je n’ai pas vraiment de problème de concentration. D’un point de vu matériel, Corexpert a su répondre à mes besoins et ce dès que j’ai commencé mon stage en me mettant à disposition un ordinateur. »
Gautier : « J’ai vécu le premier confinement en étant en cours en distanciel, et le télétravail n’est pas si différent. Un bilan régulier de l’état d’avancement du projet, que je réalise en autonomie, est effectué avec mon supérieur. De plus, dans ce bilan on évoque les attentes et les points à améliorer. Ce qui est très similaire à ce qu’on fait en présentiel. Le seul point qui n’est pas évident à gérer, c’est lorsque je rencontre des points bloquants au niveau du projet, il ne faut pas hésiter à contacter ses collègues pour demander un support. »
Gaspard : « Le stage et l’alternance m’ont permis d’évoluer dans tous les environnements. En effet j’ai d’abord été en stage pendant six mois dans les locaux de Corexpert, ensuite j’ai été en alternance entre mes cours à Vichy et Corexpert à Lyon et pour finir j’ai été à 100% en télétravail à la suite de la pandémie de COVID-19. Cela m’a permis de gagner en autonomie et de trouver la formule qui me convenait le mieux pour allier ma vie professionnelle et ma vie personnelle. »
Quelle conclusion de votre expérience professionnelle chez Corexpert, quel futur ?
Christophe : « Je pense que c’est un peu tôt pour parler du futur mais je suis très satisfait de Corexpert et travailler dans l’architecture Cloud qui me passionne pour le moment. »
Gaspard : « À la suite du stage et de l’alternance, Corexpert m’a donné l’opportunité de continuer avec eux, je fais donc maintenant partie de l’équipe de développement en tant que développeur AWS. »