Amazon Athena ou comment analyser facilement ses données

De nos jours, il est courant d’avoir un nombre très importants de données issus d’applications et de bases de données comme par exemples des logs ou des statistiques. C’est l’analyse et le traitement de ces données qui permettent d’optimiser et de mieux comprendre les usages et d’enrichir en fonctionnalités les produits. AWS propose un large éventail de services concernant les datalakes et les solutions d’analyse de données. Dans cet article, nous allons nous pencher un peu plus sur Amazon Athena, un service managé permettant de facilement analyser des données sur Amazon S3.
En quoi consiste Amazon Athena ?
Amazon Athena est un service permettant d’interroger rapidement des données stockées dans Amazon S3 (d’autres sources seront sans doute supportées plus tard) en utilisant le langage SQL. Le service supporte de nombreux formats de fichier : CSV, JSON, ORC, Apache Parquet et Avro.
Athena est basé sur le moteur Presto 0.172 mais n’en supporte pas toutes les fonctionnalités.
Un des avantages d’Athena est de fonctionner entièrement en serverless : aucun coût d’infrastructure et pas de maintenance à gérer soi-même.
Le service est facturé en fonction du volume de données parcouru par requêtes et plusieurs méthodes existe pour optimiser le coût d’utilisation des services :
• Compresser les données ayant vocation à être analysé par Athena.
• Partitionner les données horizontalement en utilisant des préfixes dans S3.
Pour des données classées par date, nous pouvons utiliser le préfixe suivant : s3://nom-du-bucket/année/mois/jour/heure/nom-des-fichiers.csv.gzip. Cela permet à Athena de ne pas parcourir tous les fichiers à chaque requête.
• Utiliser des formats de fichier en colonne comme Parquet. De cette manière quand une requête ne porte que sur certaines colonnes, seul le volume de données de ces colonnes est facturé..
Athena n’est pas recommandé pour être un entrepôt de données (data warehouse). Pour ce besoin, il vaut mieux se tourner vers Amazon Redshift pour obtenir des performances et un résultat plus intéressant.
En continuant les comparaisons avec les services Data de AWS, Athena est limité à des requêtes SQL uniquement à la différence de Amazon EMR qui propose d’autres frameworks.
Création d’une table sur Athena
Pour pouvoir requêter des données avec Athena, il faut au préalable créer des tables avec un DDL (Data Definition Langage). Suivant la complexité de la structure de nos champs et le nombre de sources de données, les DDL peuvent vite devenir complexe à rédiger.
Voici un DDL servant à la création d’une simple Table dans Athena :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
CREATE EXTERNAL TABLE IF NOT EXISTS mydatabase.cloudfront_logs ( Date DATE, Time STRING, Location STRING, Bytes INT, RequestIP STRING, Method STRING, Host STRING, Uri STRING, Status INT, Referrer STRING, os STRING, Browser STRING, BrowserVersion STRING ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( "input.regex" = "^(?!#)([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+[^\(]+[\(]([^\;]+).*\%20([^\/]+)[\/](.*)$" ) LOCATION 's3://athena-examples/cloudfront/plaintext/'; |
Utilisation combinée avec AWS Glue
AWS Glue est un service d’ETL (Extract-Transform-Load) mis à disposition par AWS et reposant sur des indexeurs (crawlers).
Le crawler Glue est capable de parcourir et d’analyser automatiquement des sources de données afin d’en déterminer la structure et par la suite de créer des tables dans un catalogue appelé « Glue Data Catalog ». C’est ces catalogues qui sont ensuites accessibles depuis Athena.
En combinant l’utilisation du crawler Glue avec Athena, il est possible d’accéder de manière très rapide à des données déja triées.
Il est possible de planifier de manière périodique l’exécution du crawler Glue afin de réduire les interventions humaines et de faciliter l’accès aux données par le business.
Cas d’usage
Présenté lors de la RE:Invent 2017, ce cas d’usage repose sur S3, Lambda, Glue et bien sûr Athena. L’objectif est d’utiliser Athena afin de faciliter la consultation de backup de base de données.
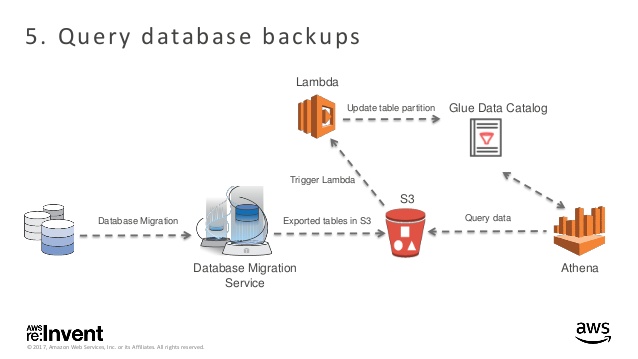 Une base de données est copiée depuis un SGBDR via AWS DMS vers S3. Les fichiers sont sauvegardés au format parquet.
Une base de données est copiée depuis un SGBDR via AWS DMS vers S3. Les fichiers sont sauvegardés au format parquet.
Le dépôt des fichiers dans S3 déclenche l’exécution d’une fonction Lambda qui va lancer le crawler Glue.
Le crawler va parcourir les données afin de mettre à jour le Data Catalog Glue.
Grâce aux catalogues, la base de données et les tables associées à celle-ci sont accessibles directement depuis Athena.
De cette manière, nous avons à disposition un backup accessible sans coût d’infrastructure associé. Seul le volume de données dans S3 et les données parcourues par Athena sont facturés.
Des outils de visualisation tels que Tableau ou Amazon Quicksight peuvent éventuellement être utilisés afin de mettre en places des dashboards.
Vous avez un projet d’entrepots de données ? Des conseils pour optimiser votre architecture existante ? N’hésitez pas à faire appel à nos experts pour vos projets !