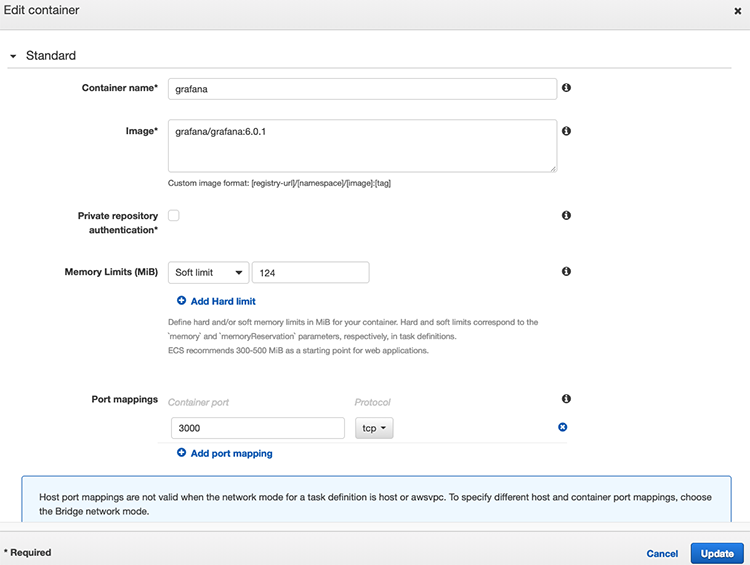
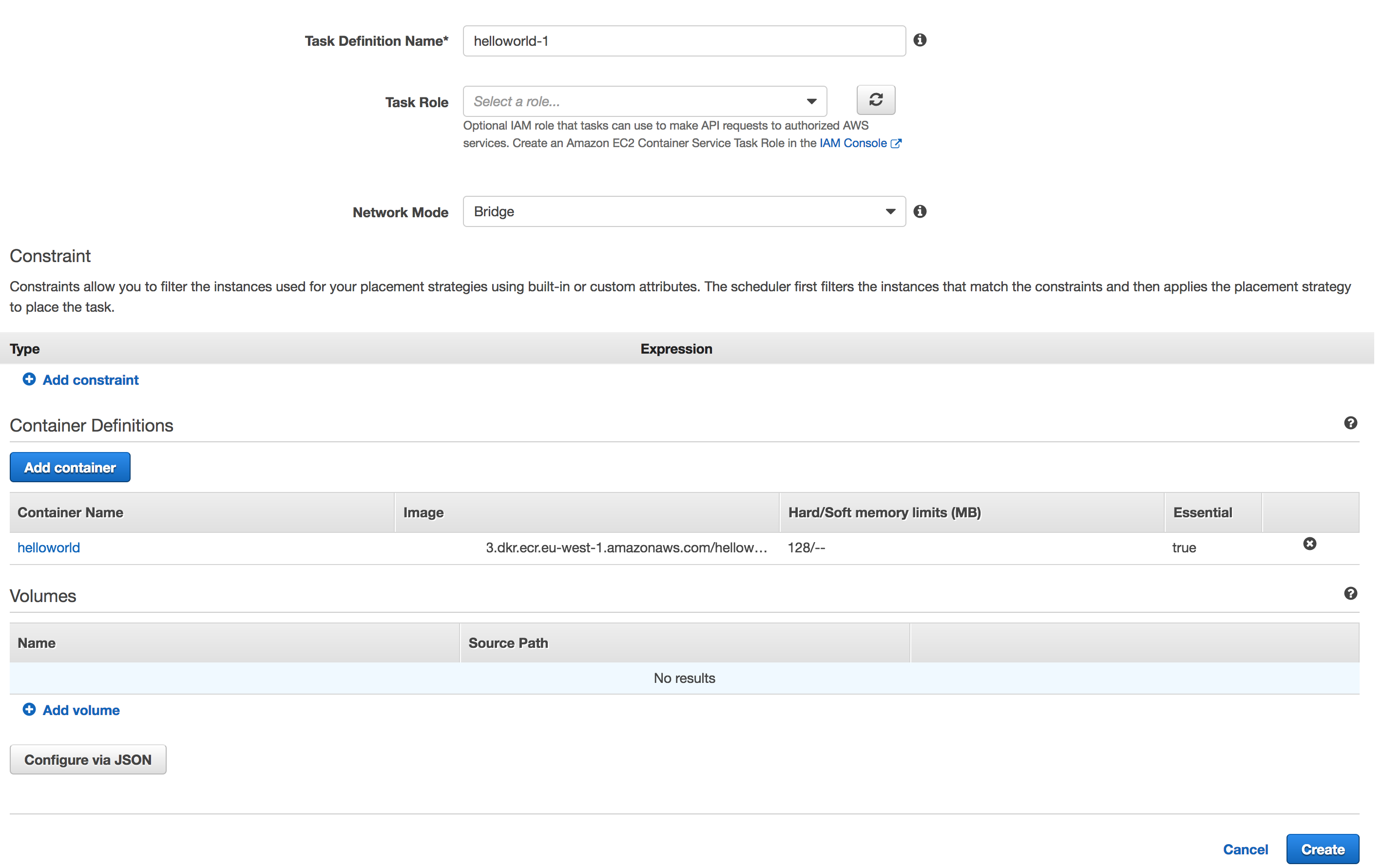
Cet article a été mis à jour en janvier 2019 avec les modifications du SLA fourni par AWS. Les compléments d’information ont été intégrés directement dans l’article d’origine.
Chez Corexpert, nos clients nous posent souvent cette question :
« On nous parle toujours de Haute Disponibilité et Très Haute Disponibilité chez AWS, mais s’engagent-ils vraiment ? Existe-t-il un SLA ? »
Qu’est ce que le SLA ?
Le SLA, ou Service Level Agreement, est le niveau de qualité et de performance contractuel d’un service ou d’une infrastructure technique. Dans le cas de AWS, fournisseur Cloud, on parlera donc bien d’un service, vue qu’on évolue dans le monde IaaS – Infrastructure as a Service !
Le SLA doit cadrer en premier lieu de quelle fourniture nous parlons, et les critères de performances sur lesquels le fournisseur va s’engager. On pourra donc parler de temps de réponse, de fonctionnalité assurée, de disponibilité complète du service etc.
SLA chez AWS
Nous allons parcourir ci-dessous les principaux services, ou services majeurs de l’offre AWS, qui possèdent un SLA à la date de rédaction de cet article. Bien évidemment la liste est non exhaustive.
Amazon Route 53 : SLA du DNS AWS
Le service DNS de AWS, Amazon Route 53, possède un SLA de disponibilité du service du niveau le plus haut possible. En effet on a ici un engagement de disponibilité de 100% sur le service, ce qui est explicité par « Amazon Route 53 n’échouera pas pour répondre à vos requêtes DNS dans le cycle de facturation d’un mois ». Pourquoi parler d’un mois ? Car AWS, s’engage, en cas d’éventuelle défaillance avérée, de vous rembourser sous forme de crédits sur ce cycle de facturation.
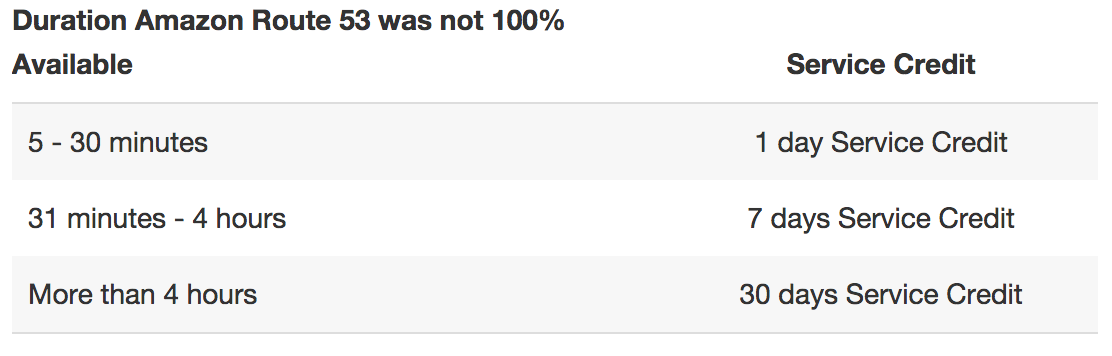
Extrait de la page SLA – Amazon Route 53 au 29 décembre 2016
Amazon EC2 ou Elastic Cloud Compute : SLA des VM AWS
Service principal de AWS, Amazon EC2 et Amazon EBS fournissent respectivement l’hyperviseur managé pour executer vos Machines Virtuelles, aka instances EC2 et le stockage virtualisé Amazon Elastic Block Store. [Le SLA a été étendu à Amazon Elastic Container Service (ECS) et AWS Fargate (deux services ayant traits aux conteneurs Docker) depuis 2018].
Le SLA des services, avec l’engagement de Amazon Web Services, est d’au moins 99.95% mensuel. Soient moins de 22 minutes.
Si une indisponibilité était avérée entre 99.95 et 99.0%, AWS s’engage à effectuer une remise de 10% en crédits AWS sur le service EC2, en deça de 99.0% de disponibilité AWS proposera une remise de 30% en crédits. [La période d’indisponibilité est maintenant de 90.0% à 99.99% depuis 2018 pour la remise de 10% de crédit AWS.]
Il est important de noter que le SLA est lié à l’état « Region Unavailable« . Si vous ne le savez pas déjà, une région est l’ensemble de plusieurs zones (2+) de disponibilités, mais dans le cadre du SLA, AWS précise que l’état « Région indisponible » vous concerne si plus d’une zone de disponibilité où vous exécutez des instances EC2 est indisponible, comprendre les instances n’ont plus accès à Internet.
L’indisponibilité de EBS est avérée lorsque les volumes de stockage ne génèrent plus d’I/O avec une file d’attente non vide.
Amazon RDS, SLA des bases de données managées AWS
Amazon RDS est le service de Base de données managée par AWS, il supporte à ce jour MySQL, Oracle, PostgreSQL, MariaDB, Microsoft SQL Server, AuroraDB. Mais le SLA proposé par AWS, concerne uniquement les instances Multi-AZ (c’est à dire avec un serveur en Stand-By mode dans une autre zone de disponibilité) des moteurs SQL : Oracle, MariaDB, MySQL & PostgreSQL. Ce SLA est de 99.95% de disponibilité du service. L’indisponibilité est avérée quand toutes les requêtes de connection échouent pendant une minute sur l’instance RDS multi-AZ.

Engagement de AWS pour RDS et remboursement en crédits au 10 janvier 2019
Amazon S3, SLA du stockage AWS
Amazon S3 est le service de stockage d’objets, il est l’un des plus anciens services de AWS, et possède une durabilité des données de 99.999999999% en mode de stockage standard. Toutefois le SLA, concerne la disponibilité d’accès à la données stockée via l’API AWS. Le SLA de Amazon S3 est donc calculé sur le comptage d’erreurs ou d’indisponibilité de l’API sur 5 minutes.
L’engagement de AWS est de conserver une disponibilité au-delà de 99.9% mensuel, ce qui représente moins de 43 minutes 36 secondes.
Si AWS ne peut assurer cette disponibilité sur la région où est stocké votre bucket S3, alors 10% de remise sur le coût de stockage S3 seront reversés en crédits, et en deça de 99.0%, alors la remise en crédit s’élèvera à 25% du coût du service Amazon S3.
[Depuis janvier 2019, ces règles ont été étendues à Amazon Elastic File System (EFS) avec les mêmes engagements que pour S3. Amazon EFS est un système de stockage de fichiers simple managé (AWS gère l’infrastructure pour vous).]
Amazon CloudFront, SLA du CDN AWS
Amazon Cloudfront est le service CDN de AWS, avec plusieurs dizaines de « Edge Locations », ce service met en cache les requêtes web selon vos comportements et pattern d’URLs choisis. Il permet des diffusions et donc des chargements de données accélérés sur les sites web et applications mobile, notamment lorsque du contenu media transite.
AWS s’engage à maintenir une disponibilité globale du service au-dessus de 99.9% mensuel (identique à Amazon S3). Les remises effectuées sur le service, en cas de défaillance avérée, également basé sur la fréquence des erreurs d’accès aux données sont identiques à celles de Amazon S3.
AWS Shield, SLA du service de protection anti-DDoS
Lancé lors du re:Invent 2016, AWS Shield est l’officialisation de la protection anti DDoS de AWS. Le service utilise et protège les autres services Amazon CloudFront et Amazon Route 53, et son SLA, ramené sur des périodes de 24 heures, est lié directement aux SLA des produits cités précédemment. On pourra donc traduire ce SLA, par un simple rappel que l’utilisation du service AWS Shield devant Amazon CloudFront ou Amazon Route 53 ne modifie pas leur SLA.
Amazon API Gateway, SLA sur la gestion des API
Depuis janvier 2019, AWS s’engage à assurer une disponibilité de 99.95% mensuel du service Amazon API Gateway. Ce service entièrement managé facilite la gestion, la surveillance et la sécurité des API de n’importe quelle taille. En cas de rupture du service, le crédit alloué est identique à ceux de RDS : 10% de remise entre 99.0% et 99.95% et 25% de remise pour une disponibilité mensuelle moindre à 99.0%.
Amazon EMR, SLA sur les frameworks Big Data
En janvier 2019, Amazon EMR bénéfice d’un engagement en terme de disponibilité de la part d’AWS. Les frameworks Big Data gérés par le service possède un SLA de 99.9% mensuel.
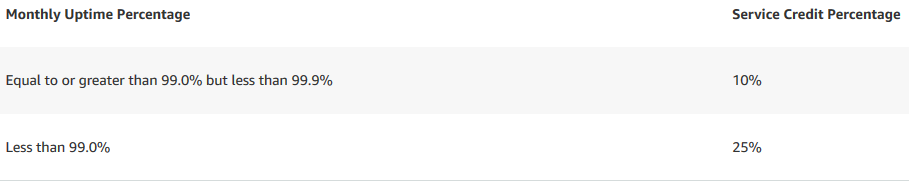 Engagement de AWS pour EMR et remboursement en crédits au 10 janvier 2019
Engagement de AWS pour EMR et remboursement en crédits au 10 janvier 2019
Amazon Kinesis, SLA sur la gestion des données en streaming
Amazon Kinesis traite de la collecte, du traitement et de l’analse de données en streaming en temps réel. Le SLA sur lequel s’engage AWS depuis janvier 2019 touche trois composants principaux de Kinesis : Videos Streams, Data Streams et Data Firehose. L’engagement de disponibilité des services est de 99.9% mensuel avec une remise de 10% à 25% en cas d’indisponibilité.
Synthèse des SLA chez AWS
| Service AWS |
SLA mensuel |
SLA minutes/mois |
| Amazon Route 53 |
100.00 % |
0 seconde |
| Amazon EC2 |
99.99 % |
4 minutes 30 secondes
|
| Amazon RDS |
99.95 % |
21 minutes et 36 secondes |
| Amazon S3 |
99.90 % |
43 minutes et 12 secondes |
| Amazon CloudFront |
99.90 % |
43 minutes et 12 secondes |
| AWS Shield |
Cf. CloudFront ou Route 53 |
Cf. CloudFront ou Route 53 |
AWS API Gateway
|
99.95 % |
21 minutes et 36 secondes |
Amazon EMR
|
99.90 % |
43 minutes et 12 secondes |
Amazon Kinesis
(Data / Videos Stream /
Data Firehose
|
99.90 % |
43 minutes et 12 secondes |
Calcul du SLA d’une infrastructure AWS
Partons d’une infrastructure Web App, relativement classique. Elle est composée de plusieurs serveurs applicatifs frontaux, ici EC2 C4.Large, le code exécuté est le même sur chaque instance, et nous avons une redondance multi-zone de disponibilités. La base de données est un MySQL sur RDS en Multi-AZ (Stand-By Instance). Les éléments statiques du sites sont stockés sur S3. CloudFront, est placé devant le Load Balancer, il met en cache les éléments statiques de S3 et reroute les autres requêtes sur le LoadBalancer. Route53 gère le nom de domaine du site.
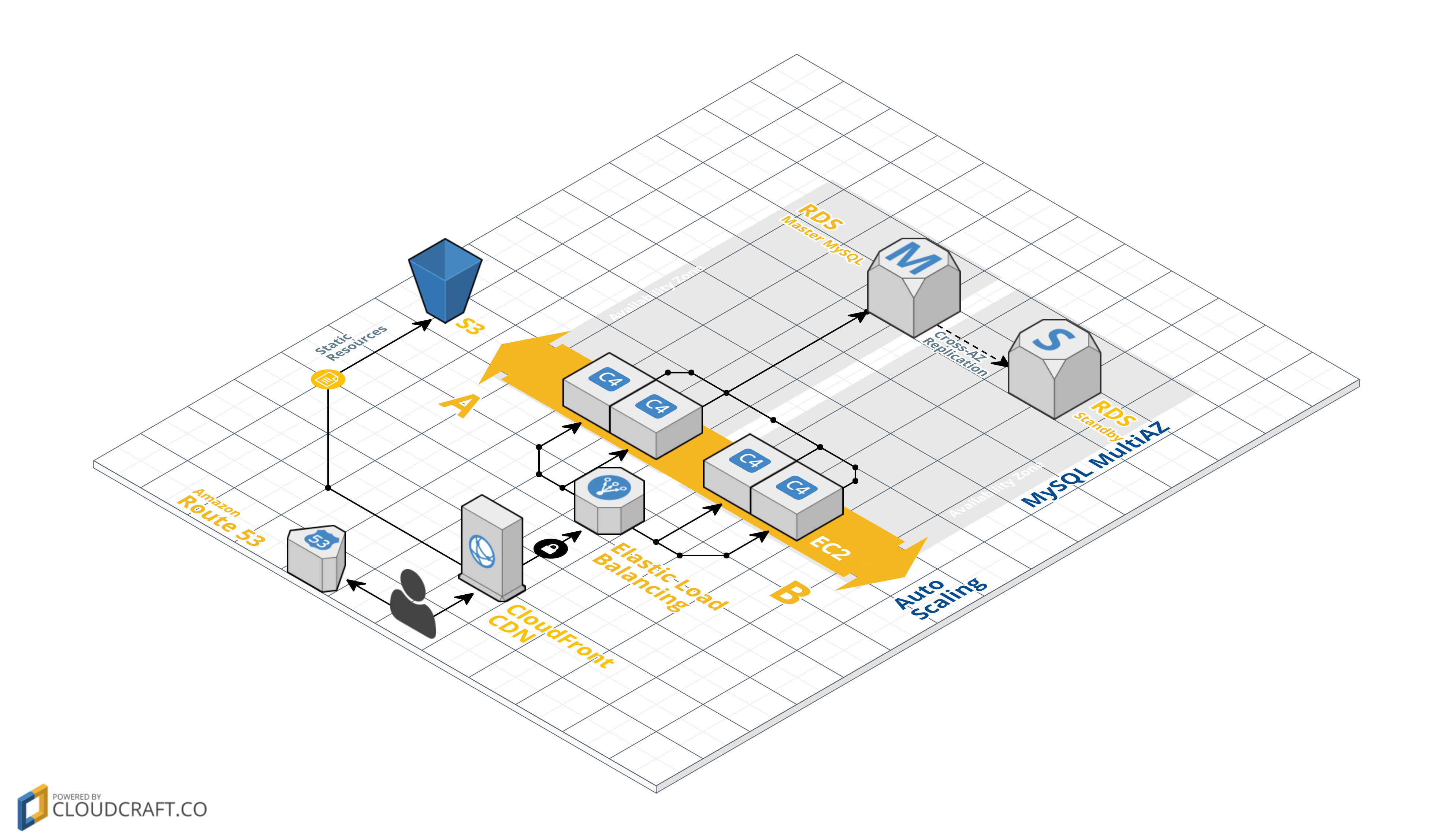
Infrastructure Web : Amazon Route 53, CloudFront, S3, EC2 et RDS
Voici comment nous pouvons calculer le SLA de cette infrastructure, bien entendu celui-ci est dans le cas d’une défaillance de tous les services AWS utilisés sur une région, et dans le cadre du SLA de chacun de ses services. Dans ce cas l’infrastructure ne peut prétendre à un SLA supérieur sans redondance supplémentaire.
- RDS Multi-AZ MySQL : SLA de 99,95 %
- EC2 : SLA de 99.95 %
- CloudFront : SLA de 99.9 %
- S3 : SLA de 99.9%
- Route 53 : 100.0 %
Le SLA de l’infrastructure brute sera de :
99.95% x 99.95% x 99.9% x 99.9% x 100% = 99,70 %
Si l’on considère que l’indisponibilité S3 n’est pas critique pour la conservation de la disponibilité de l’infrastructure web (par exemple une API) et qu’on gère via Route 53 l’éventuel downtime de CloudFront en pointant vers le Load Balancer en secours, nous gagnerons 0,2% de SLA juste par modification et optimisation du Design de l’infrastructure :
99.95% x 99.95% x 100% = 99,90 %
N’hésitez pas à poser vos questions ou nous contacter pour plus d’informations.