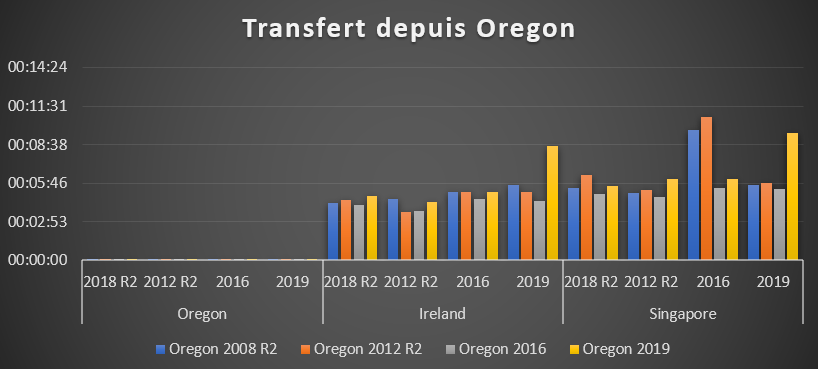
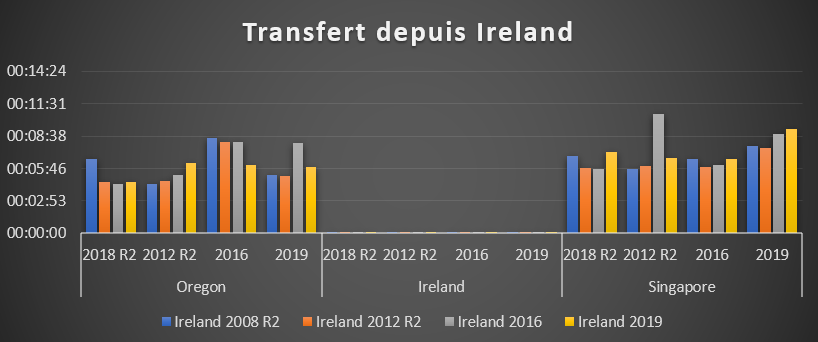
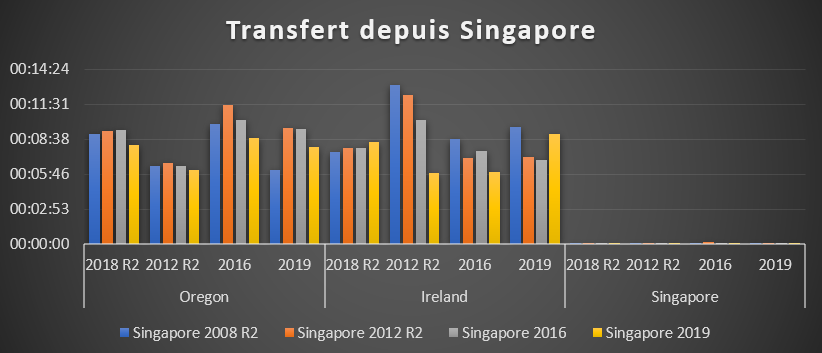
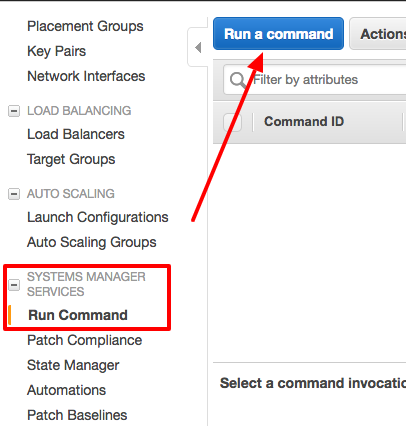
Big Data dans le cloud : Data Science as a Service

Cas d’utilisation dans la Data Science
Le client, Sanofi, troisième entreprise mondial selon le chiffre d’affaires dans le secteur de la santé, pose la problématique de créer un écosystème applicatif pour traiter et analyser l’arrivée d’un flux constant de données cliniques (essais, données patients, etc…). L’environnement se doit d’être sécurisé du fait du recueillement d’informations sensibles liées au monde médical.
Le besoin est très spécifique et fait partie du domaine du Big Data et de la Data Science.
Cela demande, d’une part, la création d’un data center capable d’assurer le stockage d’une volumétrie en constante augmentation et d’autre part la création d’outils permettant d’analyser les données pour en extraire de la valeur métier.
La donnée en question est acquise régulièrement via des laboratoires et tierces entreprises. Un traitement indispensable d’anonymisation, de formatage, et de compression est nécessaire avant d’être ingéré dans le data center.
En moyenne, on ingère 1 Téraoctet de donnée clinique tous les mois pour être traitée et stockée.
Pour rendre la donnée stockée utile, il faut assurer une haute disponibilité et la rendre requêtable d’une façon flexible, performante et en minimisant les coûts, étant donné qu’il s’agit d’une grande volumétrie de data.
En même temps, il faut assurer la sécurité de la donnée pour garantir la confidentialité du client.
Une fois accessible, une application web donnera accès à cette donnée aux utilisateurs, principalement des Data Scientists (internes ou prestaires du client) pour l’analyser.
L’application doit permettre aux Data Scientists de provisionner en « self-service » des machines virtuelles capables d’exécuter des opérations de statistique, big data et machine learning, exigeantes en termes de puissance de calcul.
On doit de même être capable de tracer les coûts par utilisateur ainsi que les flux de données depuis le data center crée.
Une infrastructure de ce genre et des machines dédiées au Data Science de cette puissance auraient un coût très élevé sur des environnements «on-premise».
Dans le cloud on va pouvoir répondre avec des solutions scalables, en donnant accès à des ressources facturées à l’utilisation avec des architectures à la hauteur des plus grandes exigences de sécurité.

Data Science as a Service
Data Lake
Pour répondre à la problématique du stockage de la data on propose un data center particulier, AWS Data Lake.
Data Lake est un data center centralisé pour tout type de donnée (structurée ou pas) et accessible à plusieurs services comme AWS Glue, AWS Athena, AWS API Gateway et ce d’une façon performante et enrichissante du point de vue métier.
AWS Service Catalog
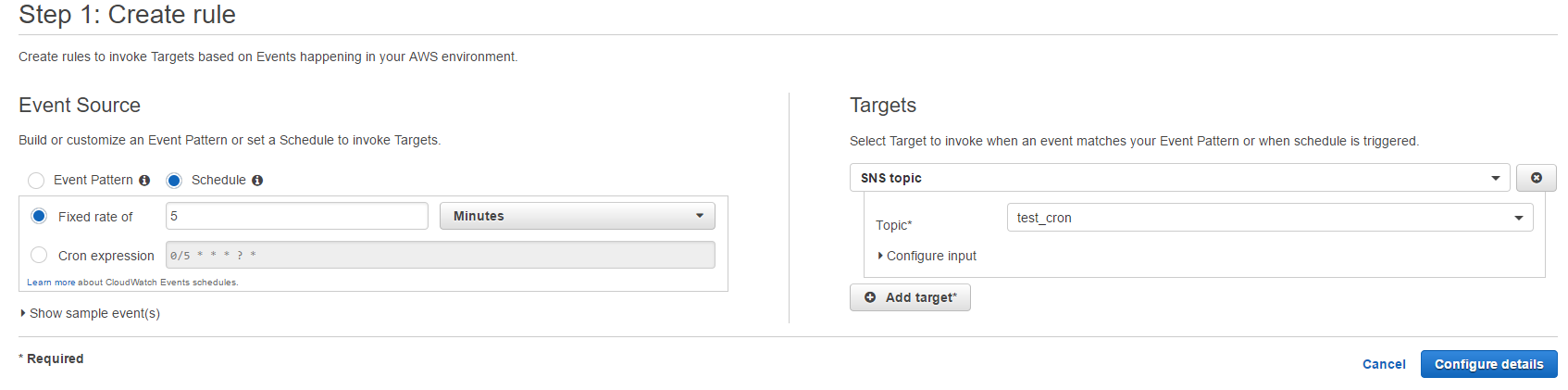
Ensuite, pour donner accès aux utilisateurs à la donnée stockée nous faisons appel à AWS Service Catalog. Ce service nous permet de provisionner des machines virtuelles (AWS EC2) pour lesquelles on définit la capacité de calcul (Processeurs, CPU, RAM, débit, …) avec des environnements de travail préchargés : langages (Python et R), librairies et outils définis en amont dans des templates Cloudformation.
Service Catalog nous permet de générer un catalogue de machines, chacune avec un environnement de travail spécifique pour répondre aux différents besoins des utilisateurs.
Pour répondre aux besoins en termes de puissance, on choisit les m5.2xlarge, la toute dernière génération d’instance d’AWS, avec des Processeurs Intel Xeon® Platinum 8175 d’une fréquence maximale de 3,1GHz, 8 processeurs virtuels et 32 Gio de mémoire.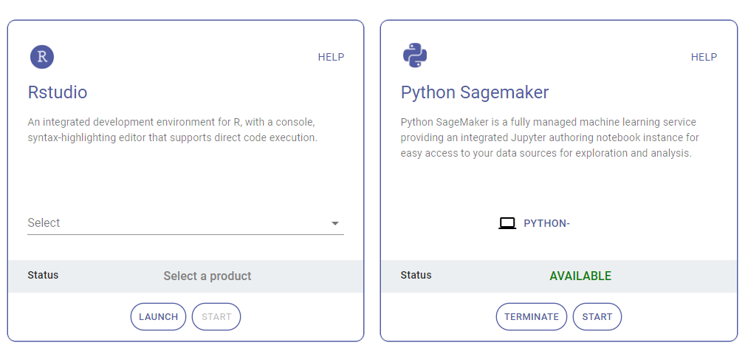
Le prix d’une machine on premise equivalente est proche de 6000 euros.
Grace au modèle de facturation à l’utilisation, on peut donner accès à ces machines aux utilisateurs à un prix de 0,35€ par heure.
Avec Service Catalog on fait aussi la gouvernance de tous les produits provisionnés. On peut provisionner, terminer, hiberner, réveiller nos machines instanciées, à l’image de notre catalogue de produits, d’une façon rapide et flexible.
Ceci va nous permettre entre autres d’avoir une traçabilité complète des produits, leur durée de vie et donc aussi les coûts générés.
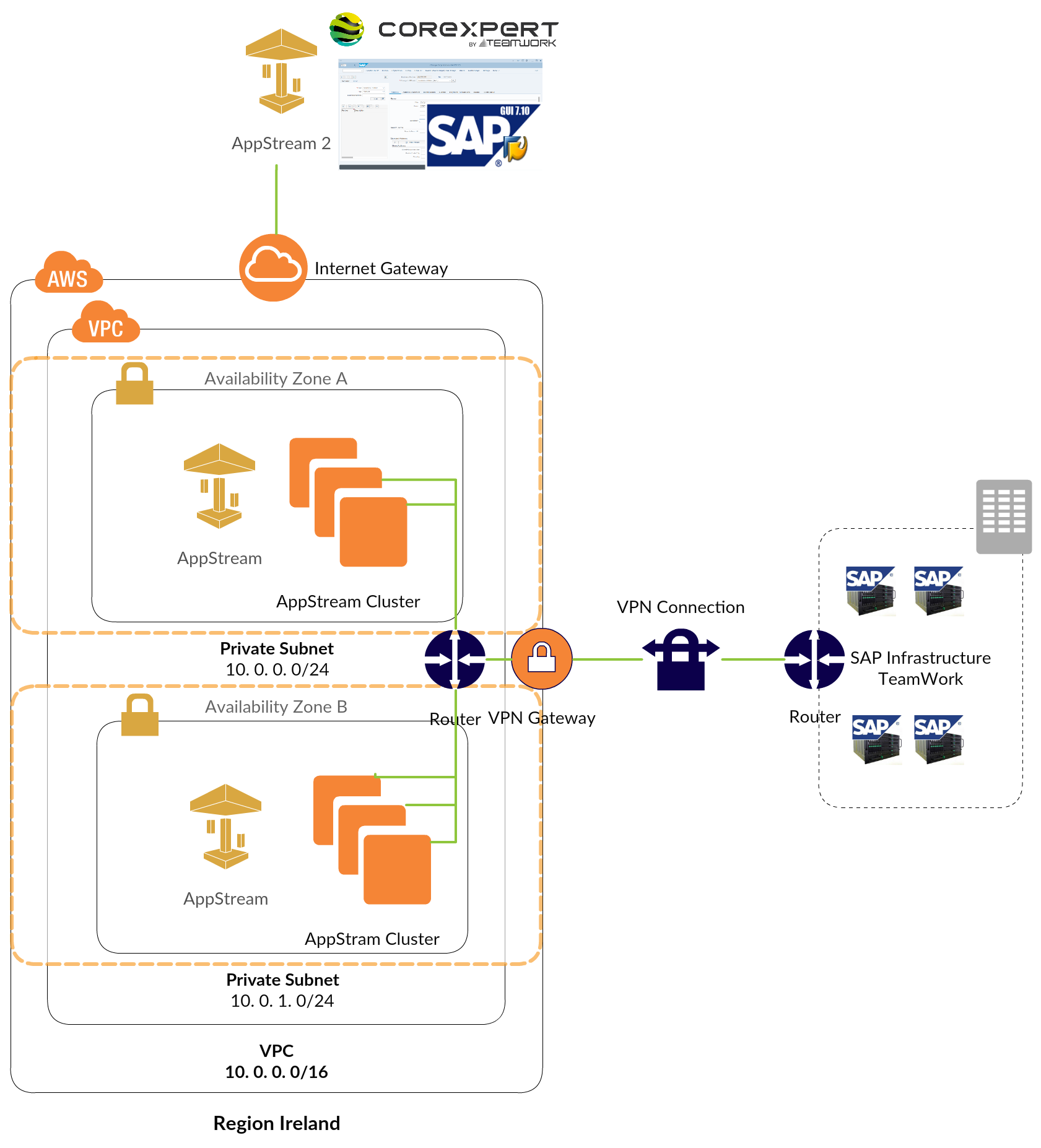
Architecture serverless
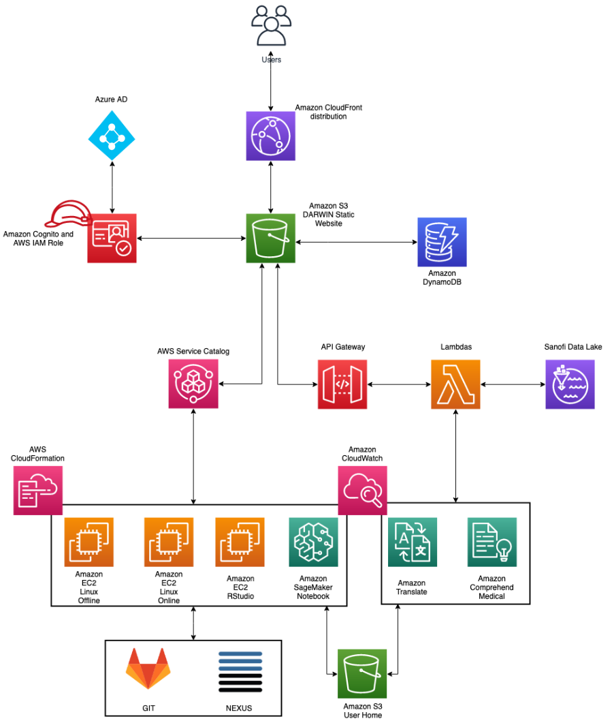
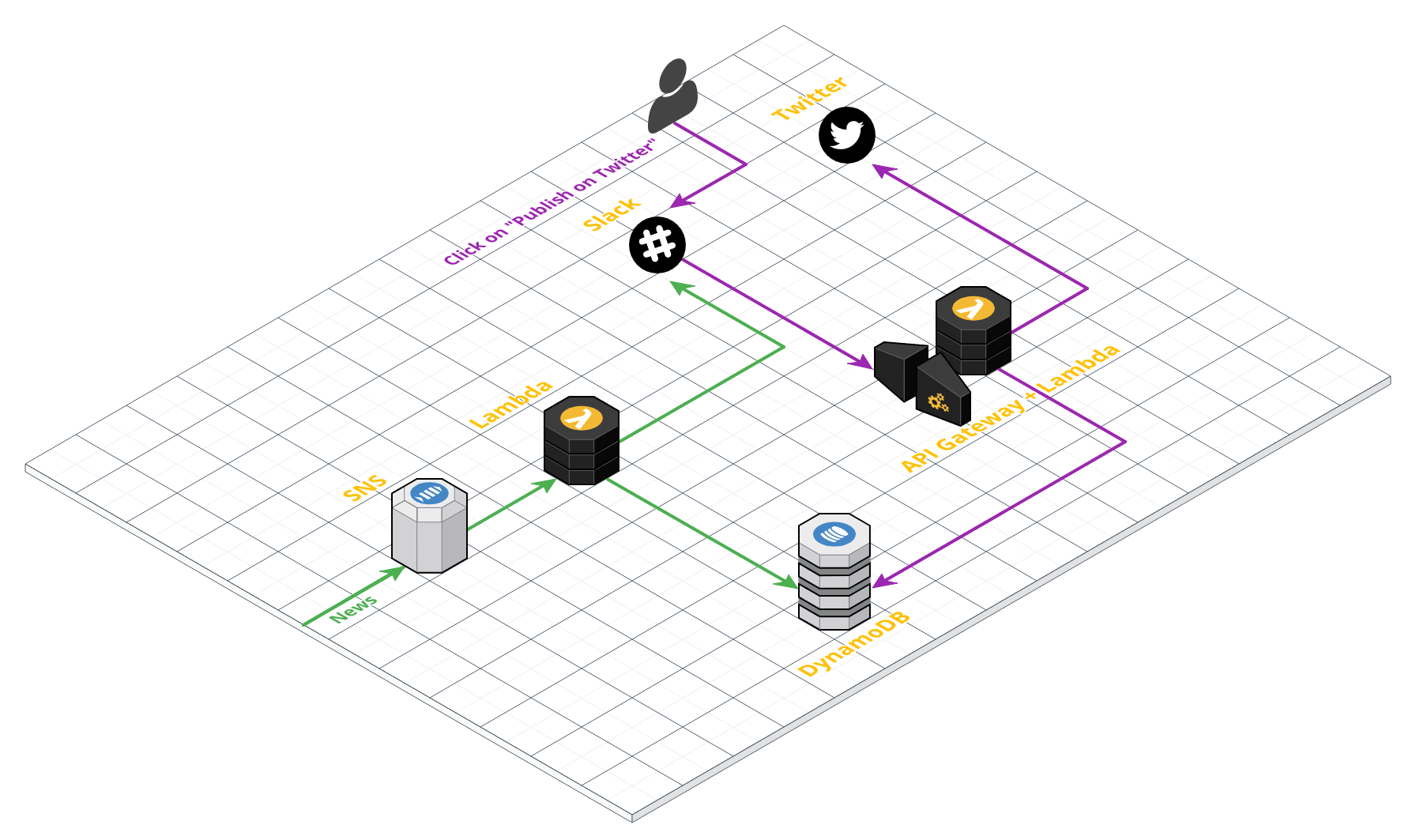
L’architecture de la partie web utilise les briques classiques AWS d’une « single web page application », stockée dans un Amazon Bucket S3 délivrée par le CDN d’AWS, Amazon Cloudfront.
Pour l’authentification, nous utilisons AWS Cognito, lié au LDAP du client donnant accès aux appels API, créée avec AWS API Gateway.
On utilise la base de données No-SQL, Amazon DynamoDB pour stocker toutes les données nécessaires au fonctionnement de l’application.
L’ensemble de l’exécution du code de la partie backend repose sur AWS Lambda.
Ensuite, Service Catalog sert à provisionner et gérer les machines virtuelles, définies avec AWS CloudFormation.
La donnée clinique, stockée dans AWS Lake Formation, se retrouve dans des Buckets S3 « montés » au sein des machines virtuelles, dans un réseau isolé, afin de protéger l’accessibilité de la donnée.
Le versioning des projets sauvegardés par les utilisateurs et l’installation de librairies sont gérés grâce à des Git et Nexus internes pour garder le réseau fermé et éviter toute fuite de données.
Retour client
Le projet, toujours en cours, avec des nouvelles évolutions, réalisé par trois personnes, a été mis en production en moins de 6 mois. Et selon notre client :
« Travailler dans le cloud nous a permis en temps record de déployer une solution à une problématique interne qui autrement aurait nécessité plus de temps, de budget et des solutions on-premise qui auraient complexifié le projet et obligé à faire un plus grand investissement en termes de ressources. »
Notamment l’accès aux machines virtuelles de telles capacité ou d’autres services plus spécifiques comme l’Intelligence Artificielle, ouvrent les portes à la conception de solutions dans des domaines plus spécialisés.